<< cont. from part 1
Internet Audio
The Internet is a global collection of interconnected networks that permits transmission of diverse data to one or many users. A network is a collection of computers sharing resources between them; the Internet is a network of networks. The advantage of internetworking is clear-the more systems online, the greater the resources available to any single user.
The Internet was born in September 1969 when packet switching was demonstrated at the University of California, Los Angeles. In December 1969, the Advanced Research Projects Agency (ARPA) of the Department of Defense officially debuted ARPANET by linking four computers in California and Utah with packet-switching lines. In 1984, the MILnet was partitioned off for military use. In 1987, seeking a way to link five supercomputers as well as regional networks, the National Science Foundation (NSF) founded the NSFNET. In 1990, the NSF decommissioned the ARPANET and greatly expanded its own network; the NSFNET became the high-speed backbone of the U.S. portion of the Internet.
The Internet operates on protocols defined by the Department of Defense. They are provided in Request for Comments (RFC) documents published by the Defense Data Network Information Center. Some of the basic specifications and documents that define implementation of the Internet are shown in Table. 3. The communication and message routing standard that forges the links that form the Internet is a set of documents called the Transmission Control Protocol/Internet Protocol (TCP/IP).
Using these protocols, networks can share information resources, thus forming the Internet. For example, the NSFNET ties together regional domestic networks such as WESTnet,
Table 3 The Department of Defense defined the protocols used in the Internet;
these are defined in military specifications and RFC documents.
SURAnet, and NEARnet, as well as wide area networks such as BITNET, FIDOnet, and USENET that provide links to foreign networks. The result is a complex global map of computer systems.
The Internet is a packet-switched network. A user sends information to a local network, which is controlled by a central server computer. At the server, the Transmission Control Protocol (TCP) parses the message, placing it in packets according to the Internet Protocol (IP), with the proper address on each packet. The network sends the packets to a router computer that reads the address and sends the packets over data lines to other routers, each determining the best path to the address. Packets may travel along different routes. This helps spread loads across the network and reduces average travel time.
However, real-time transmission can be difficult because packets can be delivered out of order, delivered multiple times, or dropped altogether. When the packets arrive at the destination address, the information is assembled and acted upon.
To illustrate the structure used to route data, the IP header is shown in Table. 4. This header is contained in an IP datagram, contained in every information field conveyed along the Internet, and is based on a 32-bit word.
The Version specifies the current IP software used; the Internet Header Length (IHL) specifies the length of the header; Type of Service flags indicate reliability and other parameters; Total Length gives length of datagram; Identifier identifies the datagram; Flags specify if fragmentation is permitted; Fragment Offset specifies where a fragment is placed; Time to Live measures gateway hops; Protocol identifies the next protocol such as TCP following the IP; the Checksum can be used for error detection; Source Address identifies the originating host; Destination Address identifies the destination host; Options can contain a route specification and padding completes the 32-bit byte; the Data field contains the TCP header and user data, with a maximum total of 65,535 8-bit octets in the datagram.
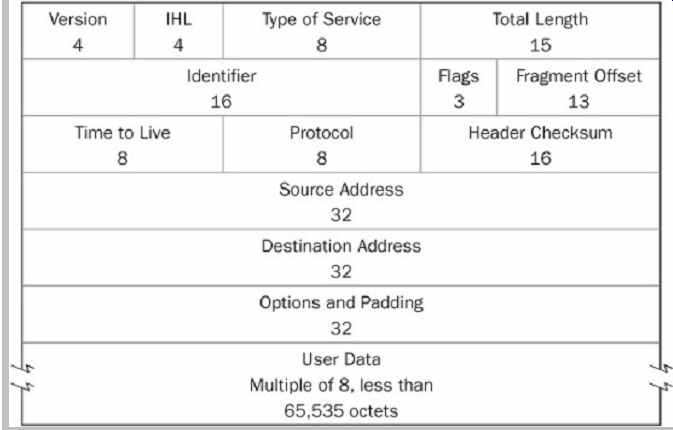
Table 4 The internet Protocol (IP) header field contains 32-bit bytes to
identify and route IP datagrams over the Internet.
Packet networks such as the Internet operate on a first come, first-serve basis thus throughput rate can be unpredictable. There is no bandwidth reservation; the Internet cannot guarantee a percentage of the network throughput to the sender. The number of packets delivered per second is continuously variable. Buffers at the receiver can smooth discontinuities due to bursty delivery, but add delay time to the throughput. Finally, packet networks such as the Internet operate point to point. A message addressed to multiple receivers must be sent multiple times; this greatly increases bandwidth requirements for multicasting. To overcome this, new transmission protocols have been developed for multicasting as described below.
In the same way that the Post Office does not need a special truck to send a letter from one address to another, but rather routes it through an existing infrastructure, the Internet sends information over its infrastructure according to standardized addresses. For example, a user at the University of California (UC), Berkeley, sending a message to Dartmouth would log onto the UC Berkeley campus network, and a router may direct it to BARRNet, the Bay Area Regional Research Network, which may route it to the NSFnet backbone, which may route it to NEARnet, the New England Academic and Research Network, which may route it to the Dartmouth campus network, and to the individual user account.
Each Internet address is governed by the Domain System Structure, a method that uniquely identifies host computers and individual users. When the Internet was first created, six high-level domains were created to distinguish between types of users: com(commercial), edu (education), gov (government), mil (military), org (other), and net (network). Many other domains have subsequently been created.
Access to the Internet requires a computer, a communications link such as a LAN connection or a modem, and a gateway. Historically, universities, corporations, and governments have provided Internet access to their students and employees via in-house computer systems. Subsequently, the Internet was made available through networks such as America Online, as well as communications companies such as AT&T. Broadband connections have replaced modem connections.
Internet bit rates are often variable and the average rate is not always sufficient to convey high-quality music in real time. The system is also susceptible to time delays from encoding and decoding latencies, routing and switching latencies, and other transmission limitations. Because the Internet is a packet-based system, it is inherently difficult to convey a continuous, time-sensitive music signal. One method to overcome these limitations is to convey music instructions instead of music waveforms. For example, with a maximum bit rate of 32.5 kbps, MIDI can convey 16 multiplexed channels of information. Although latencies from 1 ms to 20 ms are not uncommon, real-time, interactive networked performances among MIDI instruments and live performers have demonstrated the system's utility.
Voice over Internet Protocol (VoIP)
Voice over Internet Protocol (VoIP) is a transmission technology mainly used to deliver speech and voice messaging over IP networks such as the Internet using packet-switched methods. In other words, VoIP is an
"Internet telephone call." In VoIP, an audio signal is converted from analog to digital form, compressed and translated into IP packets, and transmitted over the Internet; the process is reversed at the receiver. VoIP is separate from the public switched telephone network (PSTN). VoIP technology is also referred to as Internet telephony, IP telephony, broadband telephony, and voice over broadband (VoBB). VoIP promotes bandwidth efficiency and low calling cost, and users range from individuals to large corporations. In some VoIP systems, the voice data is encrypted. In transport mode, only the payload audio data is encrypted and the packet header data is not. In tunnel mode, the entire packet is contained in a new protected packet.
VoIP can be implemented using either open-source or proprietary standards. Some examples include H.323, IMS, SIP, RTP, and the Skype network. A VoIP service provider may be needed. Several different methods are used to connect to these services. An analog telephone adapter can be placed between a telephone jack and an IP network broadband connection; this provides VoIP to all connected telephones. Alternatively, dedicated VoIP phones connect directly to the IP network through Wi-Fi or Ethernet; they can place VoIP calls without a computer. Alternatively, Internet phone "softphone" software can be used on a computer to place VoIP calls; no other hardware is needed.
The IP Multimedia Subsystem (IMS) is used to coordinate mobile telephony with Internet telecommunications. This unifies voice and data applications such as telephone calls, voice mail, faxes using the T.38 protocol, email, and Web conferencing.
VoIP offers the advantage of lower cost. For example, Internet access is billed by data (Mbyte) which is cheaper than telephone billing by time, and multiple simultaneous calls may be placed on one line. However, the IP network is less reliable than the traditional circuit-switched telephone system. IP data packets are more prone to congestion; for example, lost or delayed packets may result in a momentary audio dropout. The IEEE 802.11e amendment to the IEEE 802.11 standard provides modifications to the Media Access Control (MAC) layer, which mitigates data delay problems in VoIP.
Digital Rights Management
File formats such as MP3, WMA, and AAC are widely used to disseminate music over the Internet via downloading.
The compressed files permit efficient storage of music on distribution servers, as well as efficient transmission over IP networks. Unfortunately, they can also be used to freely share copyrighted music. Digital Rights Management (DRM) systems can be used to encode music for Internet delivery, for storage in portable players, or for recording on discs. A DRM system establishes usage rules; for example, it might limit playback to one or a few devices, limit the number of playbacks, establish a time limit, or impose no restrictions at all.
DRM systems control the use of intellectual property content, restrict its copying, and identify illegal copies in e-commerce systems. In short, DRM provides secure exchange of intellectual property in digital form. Although no single standard has been universally accepted, various systems have been devised so that copyright-protected music can be distributed via the Internet. They define how content can move from various formats to various devices.
Ideally, a DRM system should be platform-independent, have minimal object code file size, require minimal computation, and be revocable and renewable. A DRM system should also be reliable, flexible, unobtrusive, and easy to use. DRM is more than copy-protection; it establishes copy limitations and defines how a copyright holder can be paid for the copy.
DRM systems rely on numerous technologies.
Cryptography can be used to allow secure delivery between authorized parties. Content is transmitted and stored in an encrypted form to prevent unauthorized copying, playback or transmission, and recordings cannot be downloaded or played by others. Authentication is used so that properly encoded data can be read only by compliant devices and media. Cryptography is discussed below. Watermarks can be placed in files to prevent unauthorized copying, and to identify copies made illegally in spite of the DRM protection. Water-marks are discussed below. Audio fingerprints can be used to identify content, and to limit playback. A content-based identification system extracts unique signature characteristics of the content and stores them in a database. Audio fingerprints are discussed below.
Other e-commerce considerations include methods for electronic transaction. For example, anti-copy protection can be placed in every audio file, so that only a legally designated user can play it. Users must first obtain a "passport" for authorization to download music. The passport resides on the hard disk and it stamps each downloaded file so that only that user can play it and so it can be traced if necessary. If the content owner permits it, the user may make a one-time copy of the music for playback on any player.
A Rights Expression Language (REL) is used to establish and communicate usage rules. In some case, XML (eXtensible Markup Language) is used as a format.
Both open-source and royalty-bearing RELs are used.
XrML (eXtensible rights Markup Language) is a rights expression language that describes aspects such as digital property rights language and self-protecting documents.
This protocol does not define implementation aspects such as encryption or watermarking. XrML uses a license and grant method; a user is granted a right, for example, to download a product resource. This right is contained in a license issued to the user (or principal). Multiple rights may be granted relating to different content resources; for example, such as different rights to play or copy different material. A grant may contain conditions that must be fulfilled before the right is authorized. A user may need an encryption key to unlock content resource. XrML is managed by Content-Guard.
The MPEG-21 standard is an example of a framework that describes e-business mechanisms including rights management and transaction metadata using a rights data dictionary and a royalty-bearing REL based on XrML.
However, any XML-based REL can be used within MPEG 21. MPEG-21 defines the description of content as well as methods for searching and storing content and observing its copyright. MPEG-21 is formally titled "Multimedia Framework" and is described in the ISO/IEC 21000-N standard.
Extensible Media Commerce Language (XMCL) is a language used to specify rights in digital media. It can be used in conjunction with ODRL. Open Digital Rights Language (ODRL) is an XML scheme for expressing digital rights. A signed license authorizes use of a resource; each copy is cryptographically unique to the licensee. The Light Weight Digital Rights Management (LWDRM) system marks content with the user's digital signature. If a user's copy of protected content is released for general distribution, copies can be traced back to the original user. Files are protected by Advanced Encryption Standard (AES) encryption as well as proprietary watermarking. Local media format (LMF) files are unique to the computer they are created on and cannot be played elsewhere. Signed Media Format (SMF) files may be fair use copies and have different levels of playback restrictions. XMCL was developed by RealNetworks.
A number of open source DRM systems have been developed. Open IPMP (Intellectual Property Management and Protection) describes DRM tools for user and content identification and management such as cryptography, digital signatures, and secure storage. Symmetric encryption is used for content, and asymmetric encryption is used for licenses. ODRL is used within Open IPMP.
Open IPMP conforms to the Internet Streaming Media Alliance, ISMA 1.0. Media.
The consumer's convenience and fair use must be respected. DRM systems must balance their effectiveness versus usability. Generally, they discourage casual copiers, but fall short of complete protection against professional pirates and determined hackers. Legal recourse is relied upon to limit the activities of the latter two groups. One pitfall is that attack software developed by a few pirates can be disseminated to casual copiers as easily as the music files themselves.
Audio Encryption
In many applications it is important to protect copyrighted music content against both dedicated and casual piracy.
Encryption may be used to prevent copying, watermarking may identify properties of the content, and fingerprinting can identify the content itself. To be useful, these abilities must be robust even as content moves across many platforms and media in various incarnations. Ideally, a content-protection system would offer these capabilities: rights management, usage control, authentication, piracy deterrence, and tracking. However, these technologies must also be supported by legislation.
Cryptography provides one method to protect the content of files. With cryptography, data is encrypted prior to storage or transmission, then decrypted prior to use.
One early advocate was Julius Caesar; he encrypted his messages to his generals by replacing every A with a D, every B with an E, and so on, using rotational encoding.
Only a legitimate recipient (someone who knew the "shift by 3" rule) could decipher his messages. This provided good security for the Roman Empire, circa 50 B.C. Today, encryption codes are more complex. The encryption algorithm is a set of mathematical rules for rendering information unintelligible. It may consist of a mathematically difficult problem such as prime number factorization, or discrete logarithms. The original message is called the plaintext and the encrypted message is the ciphertext. To decrypt a file, a "key" is used to decipher the data. For example, the Caesar "shift by n" code can use different values of n, where n is the key.
A modern key may be a binary number, perhaps from 40 to 128 bits in length. In many applications, there is a public key that many users can employ, as well as private keys reserved for privileged access. In many audio file formats, audio data is placed into frames; the frame may also include a frame header with auxiliary information about the frame to assist decoding. A key could be placed in the header, informing the decoder that the file may be decoded if the user is authorized to do so. I llegitimate files, even copied from legitimate sources, would lack the key.
Likewise, unauthorized decoders could not play back legitimate files. However, if the audio data is separated from the key, or if the key is hacked, the audio file could be played or copied without restriction. Encryption may also require a severe computation overhead, or a small increase in file size. Of course, encryption does not offer protection after a file has been decrypted.
Generally, publicly known encryption codes are preferred. Although the codes can be attacked literally using textbook means, the codes have been well-studied by experts and the codes' weaknesses are well understood. In that respect, many people know how the lock works, but the secret is in the keys-not the lock. A critical aspect to any cryptographic system is key management. If keys are not guarded, then even strong algorithms can be unlocked. Any system thus must consider that a weak algorithm/strong key management is preferable over strong algorithm/weak key management. In other words, the security of a strong system lies in the secrecy of the key rather than with the supposed secrecy of the algorithm.
In symmetric encryption, the original information is encrypted using a key, and the ciphertext is decrypted using the same key. Because the sender and receiver use the same key, it is vital, and sometimes difficult, to keep the key a secret. Data Encryption Standard (DES) is an example of symmetric encryption; it is a block cipher with 64-bit block size and 56-bit keys. DES is identical to the ANSI standard Data Encryption Algorithm (DEA) defined in ANSI X3.92-1981. Triple DES (DES3) uses an encrypt/decrypt/encrypt sequence with 64-bit blocks and two or three different and unrelated 56-bit keys. Blowfish uses symmetric encryption; it is a block cipher using 64-bit block size and key lengths from 32 to 448 bits. International Data Encryption Algorithm (IDEA) is an example of symmetric encryption; it is a block cipher using 128-bit keys.
In asymmetric encryption, sometimes called public-key encryption, public keys and private keys are used. The public keys are freely given to users and shared openly.
However, each user also has a private key that is kept secret. The public and private keys are related by a complex mathematical transform. To illustrate: a sender has a public and private key, as does the receiver. The sender and receiver exchange their public keys, so each has three keys. The sender encrypts messages using the receiver's public key. The receiver decrypts it with a private key; only the receiver can decrypt a message that was decrypted with the receiver's public key. Not even the sender can decrypt the message. Asymmetric encryption is often used to make online financial transactions such as credit-card purchases on the Internet. Asymmetric encryption algorithms are often used for key management applications, that is, for sending secret keys needed by symmetric encryption algorithms. The first public-key encryption algorithm was devised by RSA Laboratories in 1977.
In a "brute force" attack, an opponent tries every possible key until the plaintext is revealed. Simply put, if f (x) = y and the attacker knows y and can compute f, he or she can find x by trying every possible x. Depending on the hardware resources employed, a brute force attack on a code might discover the key to a 40-bit code in 2 ms to 2 seconds; a 56-bit key might require 2 minutes to 35 hours; a 128-bit key might require 10^16 to 10^19 years.
Cryptography codes are classified as munitions by the International Traffic in Arms Regulations for the purpose of export. Sophisticated codes cannot be placed in products for export. The encryption systems used in the DVD and Blu-ray formats are discussed in Section 8 and 9, respectively.
Audio Watermarking
Digital audio watermarking offers another security mechanism, one that is intrinsic with the audio data and hidden in it. Watermarking ties ownership to content and can verify the content's authenticity. Specifically, the aim of watermarking is to embed an inaudible digital code (or tag) into an audio signal so that the identifying code can be extracted to provide an electronic audit trail to determine ownership, trace piracy, and so on. For example, if pirate recordings appeared, an embedded watermark could be recovered from them to trace the source of the original recording. Or, a player could check for watermarks before starting playback; if the watermark is missing or corrupted (as in an illegal copy), the player would refuse to play the copy. Source watermarks can be attached to a specific media (such as DVD or Blu-ray) to identify and protect the content. Transactional watermarks are independent of the media and track usage; for example, a watermark could monitor the number of Internet downloads. Watermarking is also known as steganography, the process of concealing information within data. In some cases, the watermark itself may be encrypted.
Because watermarks alter the audio data, they must ideally be transparently inaudible to the end user, and not affect the sound quality of the audio signal. A watermark should also be robust so that it can be recovered from the audio signal, and it should have survivability so that even after other processing, such as perceptual coding, the watermark is intact. For example, a watermark should be able to persist after D/A or A/D conversion, or transmission through an AM or FM radio broadcast path. In an extreme case, it should be possible to play a watermarked analog audio signal through a loudspeaker, and re-record the signal through a microphone, with an intact water-mark. A watermark must also survive file format changes, for example, conversion from PCM to ADPCM to MP3. A watermark must also be secure so that it cannot be removed, altered, or defeated by an unauthorized user. If the watermark is attacked, it must result in a clearly degraded audio signal or produce other evidence that tampering has occurred. For example, it must overcome attempts to overwrite it with a counterfeit watermark. A watermark must also guard against false positives and false negatives. A receiver must not mistakenly identify watermark data where none exists, or misinterpret the watermark data. For example, the receiver should not refuse to play data that has a legitimate watermark, or interpret a counterfeit watermark as authentic. Finally, a watermark must not burden the file with excessive overhead data.
Simple watermarks can be realized by a few bits and this makes them easy to inaudibly embed and also makes them potentially more survivable. However, low bit-rate watermarks are more vulnerable. For example, the 16 permutations of a 4-bit least-significant bit (LSB) watermark could be easily tested and hacked. Thus, designers may consider security measures such as cryptographic keys. Watermarks can be applied to different file types such as PCM, WAV, and AIFF. In addition, watermarking can be applied to monaural or multichannel recordings at various sampling frequencies and word lengths.
Numerous audio (and video) watermarking methods have been developed. Systems may manipulate signal phase, place data in an undetectable frequency range, or employ spread-spectrum encoding. For example, with phase coding, watermark data is represented by a smooth (inaudible) phase change in certain frequency components.
However, the integrity of phase coding may be compromised by low bit-rate coding algorithms. With spread-spectrum coding, watermark data is distributed over a relatively broad frequency range, thus hiding it. The watermark is coded with necessary error correction, then modulated and multiplied by a pseudo-random noise sequence. The resulting watermark signal occupies a certain spectrum and is attenuated and combined with the audio signal as noise. At the receiver, the watermark is extracted by multiplying the signal with the same pseudo random sequence that is synchronized with the received signal; the watermark is thus de-spread. This technique can yield reliable results.
Many watermarking systems combine two or more methods to achieve a more robust solution. For example, spread-spectrum coding could use amplitude masking to shape the watermark and ensure its inaudibility. However, watermarks that use amplitude masking to prevent their audibility might risk being removed by perceptual codecs that eliminate masked or redundant signals. In another approach, watermarking data is pseudo-randomized and placed in the least-significant bits of certain words; the water-marking data adds benign noise to the audio signal.
However, the watermark is relatively easy to attack. A buried data channel technique is described in Section. 18.
Watermarking techniques optimized for digital audio signals cannot be used on executable software code, ASCII code, or other code that has zero-tolerance for errors. Other approaches must be employed for these files.
There are a number of different watermarking techniques, each with a different intent. A copy-control watermark is designed to prevent casual unauthorized copying. This watermark is embedded in the recording, and is detected by a subsequent recorder. The watermark could be coded to allow no copies, one copy, a limited number of copies, or unlimited copying. For example, in one application, a rights holder may permit a user to make an unlimited number of copies, if a licensing fee is paid. A compliant recorder would detect the watermark and its copy code, and follow its dictates. If it made a subsequent copy, it would decrement the copy number in the watermark in the new copy.
A forensic watermark might be designed to deter professional piracy. This type of watermark holds a significant amount of data so the file can be authenticated and any tampering detected, using a verification key. The file may be designed to be intentionally fragile, so that if the file is subjected to processing, the original watermark is damaged or lost, and the tampering can be thus detected.
For example, a player would detect tampering in the corrupted watermark in a pirated disc, and refuse to play that disc. An accompanying and more robust copy control watermark could identify the source.
Some MP3 ripping software automatically embeds song and artist information into the file using ID3 tags. A Track Unique IDentifier (TUID) tag can be added to a song to link it to the source album. Technologies such as these can be used by gated P2P "music download" services to track the content sold to authenticated customers.
Embedded watermarking technology has been selected for use in audio applications such as DVD-Audio, Super Audio CD (SACD) and Blu-ray disc. Similar water-marking methods can also be used for the CD.
Audio Fingerprinting
Audio fingerprinting, also known as content-based audio identification, analyzes an audio file to extract a unique signature and then uses that signature to search for a similar fingerprint in a database and thus identify the audio file. Fingerprints are primarily used for licensing and copyright enforcement. For example, a broadcast or web cast can be monitored to verify that paid advertisements are aired and song royalties are collected, or a network administrator could prohibit transmission of copyrighted material. Alternatively, fingerprints can be used to identify musical qualities, and recommend other similar music to a listener.
An audio fingerprint can be viewed as a summary that describes the characteristics of an audio file. It can provide an efficient means to search for and identify a file among many others. In many systems, features are extracted from known content and stored in a database during a training phase. Unknown content can be identified by extracting its features and comparing them to those in a large database containing perhaps a million fingerprints. The output of the system is metadata that identifies the unknown audio file, and a confidence measure. A system is shown in FIG. 5.
The method is efficient because of the compact size of the fingerprints; it is faster to search and compare them rather than the entirety of the waveform files themselves. However, the system may be compromised when the unknown signal is distorted or fragmented. Although audio fingerprinting techniques have some similarities to audio watermarking, they are considered to be different applications.

Fig. 5 An audio fingerprint system operates in two modes. A training
method is used to accumulate a database of fingerprints. An identification
mode is used to identify an unknown audio file by generating and matching its
fingerprint to one stored in the database.
Unlike a simple file name that can easily be changed to obscure a file's identity, the extracted information inherently identifies the content itself. Ideally, the reference characteristics are independent of variables such as audio format, sampling frequency, equalization, and signal distortion. A signature extraction should be possible even after a file has been processed or altered. Moreover, a signature should resist attempts to forge a signature or reuse it on other content. To do this, the features used in the fingerprint must remain relatively unaffected by changes in the signal. Similarly, a system must be reliable and avoid errors in identification. Large databases are more prone to false matches, and thus have lower reliability. A system should also be computationally efficient with compact fingerprint, low algorithmic complexity, and fast searching and matching techniques. Most systems are scalable and able to accommodate increasingly larger databases.
Fingerprints themselves should be compact to provide efficiency, yet include sufficient parameters to completely characterize the audio file and allow accurate matching.
Fingerprint identification generally comprises two steps:
extraction and modeling. Prior to extraction, the audio signal is placed into frames, windowed, and overlapped.
The signal is transformed, for example, with fast Fourier transform (FFT) or discrete cosine transform (DCT).
Feature extraction can employ many types of techniques. In many cases, critical-band spectrum analysis is used to generate perceptual parameters similar to those meaningful to the human hearing system. For example, a spectral flatness measure may be used to estimate the tonal or noise-like properties of the signal, or the energy in Bark bands may be calculated. Feature vectors are presented frame-by-frame to a fingerprint modeling algorithm. It consolidates the features from the entire file into a compact fingerprint. Various techniques can be used. For example, among other features, one model includes an average of the spectrum, average rate of zero crossing, and beats per minute. Another model uses sequences of indexes to sound classes that describe the audio signal over time.
The output stage of a fingerprint system searches the index of a database of known fingerprints in an attempt to identify the fingerprint from an unknown audio file. Metrics, such as Euclidean or Hamming distance, or correlation can be used. Various methods are used to optimize the indexing and searching of the database. When a match is found, its viability is measured against a threshold to determine the likelihood of correct identification. The MPEG-7 standard specifies numerous ways to perform audio fingerprinting and other related functions; it is described later.
Streaming Audio
When the size of the file is greatly reduced, so that it can be received as fast as it can be played, the file can be streamed. In this application, the music begins to play as soon as a buffer memory receiving the signal is filled. Data reduction algorithms can successfully reduce file size to permit downloading of files in a reasonable time. However, it is more difficult to stream audio files continuously, in real time.
Not only must the file size be small, it must also cope with the packet-switching transmission method of the Internet. Packets usually arrive sequentially, but not always, and some packets may be missing, and must be retransmitted, which incurs a delay. A buffer is needed because otherwise interruptions in the flow of data would cause interruptions in the playback signal. In addition, many different kinds of computers are used to play streaming files, with different processing power and different speeds of Internet connections. Finally, data speeds across an Internet path differ according to the path itself and traffic conditions. Thus streaming audio presents challenges, challenges that are multiplied when accompanied by streaming video, particularly if it is to be synchronized with audio.
The RealAudio format is used to stream prerecorded and live audio on the Internet. RealAudio files can be coded at a variety of bit rates, and the format supports scalability of the bitstream. A decoder can decode all the bits to reproduce a high-quality signal, or a subset of the bitstream for a lower-quality signal. This feature helps to sustain transmission when bit rate is variable or when available processor power varies. Files can be streamed from any HTTP computer; RealServer software permits better performance, more connections, and better security features. RealPlayer supports both streaming audio and video. Author, title, copyright, and other information can be included in files. Stored files can be downloaded and copied unless stored in a directory not accessible to users.
This is easily accomplished by linking the Web page to a small metafile that links to the actual media files. As with any streaming file protocol, it is important to preprocess audio files prior to streaming. Typically, a midrange (2.5 kHz) boost is added, the dynamic range of the file is compressed, and the file is normalized to 95% of maximum. SureStream-encoded files can be used for multicast streaming. The stream contains scaled files; the server identifies the client's connection speed and transmits at the appropriate bit rate. RealAudio was developed by RealNetworks.
The Internet TCP protocol is efficient for packet transmission, providing robust error correction and verification. However, the required overhead slows processors and transmission throughput speeds in general.
In addition, TCP allocates per-connection bandwidth proportional to available bandwidth, without considering how much bandwidth is needed. Thus, highly compressed files may be inefficiently allocated with too much bandwidth.
An alternative to TCP is the User Datagram Protocol (UDP); it is a simpler packet protocol without error correction or verification. Clients must request a missing packet, rather than receiving it automatically. This promotes better throughput. RealSystem servers use UDP.
RealNetworks has also developed Real-Time Streaming Protocol (RTSP), an open standard for transmitting time based multimedia content, described below.
Among its diverse capabilities, Apple's QuickTime software offers several compression options for music and speech applications, for both downloading and streaming.
QuickTime itself is not application software, but rather an extension of the computer operating system. Using the Sound Manager, media elements are stored in the movie MOV file format, allowing synchronization among diverse elements. Over 35 different file formats are supported. The Netcasting feature allows QuickTime players to play streaming broadcasts of any QuickTime media type. Data fields can store user information and audio files can include video, text, and MIDI content. The QuickTime file format is the basis for the MPEG-4 file specification, discussed later.
QuickTime is discussed in Section. 14.
Shockwave is a streaming audio package based on MPEG Layer III coding; it allows compression at bit rates ranging from 8 kbps to 128 kbps. As noted, some streaming systems employ UDP to improve reliability of transmission, but this requires special server software, and streaming may be inhibited by a firewall. In contrast, Shockwave operates with any HTTP server; dropouts are mitigated by longer buffering of audio data. Shockwave audio files are coded as SWA files. When the browser loads the HTML page, it encounters an Embed tag that identifies the Shockwave file; the browser then loads the plug-in and downloads the file. When buffering is completed, the file begins to play. Shockwave integrates with Macromedia's Director program, which is used for multimedia authoring, in which a series of frames make up a "movie." Director movies are converted to Shockwave files following data compression. Shockwave was developed by Macromedia.
The Microsoft Windows Media (WMA) Technologies platform is used to provide streaming audio and video and other digital media. Media Technologies uses a data reduction algorithm, sometimes known as MSAudio, to provide FM-quality audio at a bit rate of 28.8 kbps. In one mode, the algorithm streams 44.1-kHz sampled stereo audio at a bit rate of 20 kbps; it claims CD transparency at 160 kbps. Windows Media Encoder (WME) is used to create content; for example, WAV files can be compressed to WMA files. An ASX text metafile points to the WMA file.
The system supports multi-bit-rate encoding to create multiple data-rate streams in a single media file. Users receive the optimal stream for their connection; content is coded in the Advanced Streaming Format (ASF) native file format. Using the open architecture of the Direct-Show API , the Media Player can support files types including MP3, WAV, AVI , MIDI , QuickTime, and MPEG including MPEG-4 v.3 for video streaming. In addition, the Media Player automatically checks incoming streams for codec versions and then downloads new versions of the codec as needed.
Content from 3 kbps of audio to 6 Mbps of audio/video is supported. Both on-demand ASF files and live-encoded streams are supported. The server can automatically select a stream from a range of bandwidths. If the connection conditions change, the server can switch to a higher or lower bit rate.
Windows Media Services is the server component of the system. A single server can support thousands of simultaneous user connections; both unicast and multicast modes are supported. Transmission protocols UDP, TCP, and HTTP are supported. The Windows Media Rights Manager system reduces piracy and enables digital distribution. Customers use an authorization mechanism to play content; content can be encrypted so that it is licensed for use only as the publisher intends.