1. The physics of sound
Sound is simply an airborne version of vibration which is why the two topics are inextricably linked. The air which carries sound is a mixture of gases, mostly nitrogen, some oxygen, a little carbon dioxide and so on.
Gases are the highest energy state of matter, for example the application of energy to ice produces water and the application of more energy produces steam. The reason that a gas takes up so much more room than a liquid is that the molecules contain so much energy that they break free from their neighbors and rush around at high speed.
As FIG. 1(a) shows, the innumerable elastic collisions of these high speed molecules produce pressure on the walls of any gas container. In fact the distance a molecule can go without a collision, the mean free path, is quite short at atmospheric pressure. Consequently gas molecules also collide with each other elastically, so that if left undisturbed, in a container at a constant temperature, every molecule would end up with essentially the same energy and the pressure throughout would be constant and uniform.
Sound disturbs this simple picture. FIG. 1(b) shows that a solid object which moves against gas pressure increases the velocity of the rebounding molecules, whereas in (c) one moving with gas pressure reduces that velocity. The average velocity and the displacement of all the molecules in a layer of air near to a moving body is the same as the velocity and displacement of the body. Movement of the body results in a local increase or decrease in pressure of some kind. Thus sound is both a pressure and a velocity disturbance. Integration of the velocity disturbance gives the displacement.

FIG. 1 (a) The pressure exerted by a gas is due to countless elastic collisions
between gas molecules and the walls of the container. (b) If the wall moves
against the gas pressure, the rebound velocity increases. (c) Motion with the
gas pressure reduces the particle velocity.
Despite the fact that a gas contains endlessly colliding molecules, a small mass or particle of gas can have stable characteristics because the molecules leaving are replaced by new ones with identical statistics. As a result acoustics seldom needs to consider the molecular structure of air and the constant motion can be neglected. Thus when particle velocity and displacement is considered in acoustics, this refers to the average values of a large number of molecules. In an undisturbed container of gas the particle velocity and displacement will both be zero everywhere.
When the volume of a fixed mass of gas is reduced, the pressure rises.
The gas acts like spring; it’s compliant. However, a gas also has mass.
Sound travels through air by an interaction between the mass and the compliance. Imagine pushing a mass via a spring. It would not move immediately because the spring would have to be compressed in order to transmit a force. If a second mass is connected to the first by another spring, it would start to move even later. Thus the speed of a disturbance in a mass/spring system depends on the mass and the stiffness.
After the disturbance had propagated the masses would return to their rest position. The mass-spring analogy is helpful for a basic under standing, but is too simple to account for commonly encountered acoustic phenomena such as spherically expanding waves. It must be remembered that the mass and stiffness are distributed throughout the gas in the same way that inductance and capacitance are distributed in a transmission line. Sound travels through air without a net movement of the air.
2. The speed of sound
 FIG. 2 Calculating the speed of sound from the elasticity of air.
FIG. 2 Calculating the speed of sound from the elasticity of air.
Unlike solids, the elasticity of gas is a complicated process. If a fixed mass of gas is compressed, work has to be done on it. This will generate heat in the gas. If the heat is allowed to escape and the compression does not change the temperature, the process is said to be isothermal. However, if the heat cannot escape the temperature will rise and give a disproportionate increase in pressure. This process is said to be adiabatic and the Diesel engine depends upon it. In most audio cases there is insufficient time for much heat transfer and so air is considered to act adiabatically.
FIG. 2 shows how the speed of sound ,c, in air can be derived by calculating its elasticity under adiabatic conditions.
If the volume allocated to a given mass of gas is reduced isothermally, the pressure and the density will rise by the same amount so that c does not change. If the temperature is raised at constant pressure, the density goes down and so the speed of sound goes up. Gases with lower density than air have a higher speed of sound. Divers who breathe a mixture of oxygen and helium to prevent 'the bends' must accept that the pitch of their voices rises remarkably.
The speed of sound is proportional to the square root of the absolute temperature. On earth, temperature changes with respect to absolute zero (-273°C) also amount to around one percent except in extremely inhospitable places. The speed of sound experienced by most of us is about 1000 feet per second or 344 meters per second. Temperature falls with altitude in the atmosphere and with it the speed of sound. The local speed of sound is defined as Mach 1. Consequently supersonic aircraft are fitted with Mach meters.

FIG. 3 At high level, sound distorts itself by increasing the speed of propagation
on positive half-cycles. The result is a shock wave.

FIG. 4 In a complex waveform, high frequencies travel slightly faster producing
a relative phase change with distance.
As air acts adiabatically, a propagating sound wave causes cyclic temperature changes. The speed of sound is a function of temperature, yet sound causes a temperature variation. One might expect some effects because of this. Fortunately, sounds which are below the threshold of pain have such a small pressure variation compared with atmospheric pressure that the effect is negligible and air can be assumed to be linear.
However, on any occasion where the pressures are higher, this is not a valid assumption. In such cases the positive half cycle significantly increases local temperature and the speed of sound, whereas the negative half cycle reduces temperature and velocity. FIG. 3 shows that this results in significant distortion of a sine wave, ultimately causing a shock wave which can travel faster than the speed of sound until the pressure has dissipated with distance. This effect is responsible for the sharp sound of a handclap.
This behavior means that the speed of sound changes slightly with frequency. High frequencies travel slightly faster than low because there is less time for heat conduction to take place. FIG. 4 shows that a complex sound source produces harmonics whose phase relationship with the fundamental advances with the distance the sound propagates.
This allows one mechanism (there are others) by which one can judge the distance from a known sound source. Clearly for realistic sound reproduction nothing in the audio chain must distort the phase relationship between frequencies. A system which accurately preserves such relationships is said to be phase linear.
3. Wavelength
Sound can be due to a one-off event known as percussion, or a periodic event such as the sinusoidal vibration of a tuning fork. The sound due to percussion is called transient whereas a periodic stimulus produces steady-state sound having a frequency, f.
Because sound travels at a finite speed, the fixed observer at some distance from the source will experience the disturbance at some later time. In the case of a transient, the observer will detect a single replica of the original as it passes at the speed of sound. In the case of the tuning fork, a periodic sound source, the pressure peaks and dips follow one another away from the source at the speed of sound. For a given rate of vibration of the source, a given peak will have propagated a constant distance before the next peak occurs. This distance is called the wavelength lambda. FIG. 5 shows that wavelength is defined as the distance between any two identical points on the whole cycle. If the source vibrates faster, successive peaks get closer together and the wavelength gets shorter. FIG. 5 also shows that the wavelength is inversely proportional to the frequency. It’s easy to remember that the wavelength of 1000Hz is a foot (about 30 cm).

FIG. 5 Wavelength is defined as the distance between two points at the same
place on adjacent cycles. Wavelength is inversely proportional to frequency.

FIG. 6 (a) Periodic signal repeats after a fixed time and has a simple spectrum
consisting of fundamental plus harmonics. (b) Aperiodic signal such as noise
does not repeat and has a continuous spectrum. (c) Transient contains an anharmonic
spectrum.
4. Periodic and aperiodic signals
Sounds can be divided into these two categories and analyzed both in the time domain in which the waveform is considered, or in the frequency domain in which the spectrum is considered. The time and frequency domains are linked by transforms of which the best known is the Fourier transform. Transforms will be considered further in Section 3.
FIG. 6(a) shows that a periodic signal is one which repeats after some constant time has elapsed and goes on indefinitely in the time domain. In the frequency domain such a signal will be described as having a fundamental frequency and a series of harmonics or partials which are at integer multiples of the fundamental. The timbre of an instrument is determined by the harmonic structure. Where there are no harmonics at all, the simplest possible signal results which has only a single frequency in the spectrum. In the time domain this will be an endless sine wave.
FIG. 6(b) shows an aperiodic signal known as white noise. The spectrum shows that there is equal level at all frequencies, hence the term 'white' which is analogous to the white light containing all wavelengths.
Transients or impulses may also be aperiodic. A spectral analysis of a transient (c) will contain a range of frequencies, but these are not harmonics because they are not integer multiples of the lowest frequency.
Generally the narrower an event in the time domain, the broader it will be in the frequency domain and vice versa.
5. Sound and the ear
Experiments can tell us that the ear only responds to a certain range of frequencies within a certain range of levels. If sound is defined to fall within those ranges, then its reproduction is easier because it’s only necessary to reproduce those levels and frequencies which the ear can detect.
Psychoacoustics can describe how our hearing has finite resolution in both time and frequency domains such that what we perceive is an inexact impression. Some aspects of the original disturbance are inaudible to us and are said to be masked. If our goal is the highest quality, we can design our imperfect equipment so that the shortcomings are masked. Conversely if our goal is economy we can use compression and hope that masking will disguise the inaccuracies it causes.
A study of the finite resolution of the ear shows how some combinations of tones sound pleasurable whereas others are irritating. Music has evolved empirically to emphasize primarily the former. Nevertheless we are still struggling to explain why we enjoy music and why certain sounds can make us happy and others can reduce us to tears. These characteristics must still be present in digitally reproduced sound.
Whatever the audio technology we deal with, there is a common goal of delivering a satisfying experience to the listener. However, some aspects of audio are emotive, some are technical. If we attempt to take an emotive view of a technical problem or vice versa our conclusions will be questionable.
The frequency range of human hearing is extremely wide, covering some ten octaves (an octave is a doubling of pitch or frequency) without interruption. There is hardly any other engineering discipline in which such a wide range is found. For example, in radio different wavebands are used so that the octave span of each is quite small. Whilst video signals have a wide octave span, the signal-to-noise and distortion criteria for video are extremely modest in comparison. Consequently audio is one of the most challenging subjects in engineering. Whilst the octave span required by audio can easily be met in analog or digital electronic equipment, the design of mechanical transducers such as microphones and loudspeakers will always be difficult.
6. Hearing
By definition, the sound quality of an audio system can only be assessed by human hearing. Many items of audio equipment can only be designed well with a good knowledge of the human hearing mechanism. The acuity of the human ear is finite but astonishing. It can detect tiny amounts of distortion, and will accept an enormous dynamic range over a wide number of octaves. If the ear detects a different degree of impairment between two audio systems in properly conducted tests, we can say that one of them is superior. Thus quality is completely subjective and can only be checked by listening tests. However, any characteristic of a signal which can be heard can in principle also be measured by a suitable instrument although in general the availability of such instruments lags the requirement. The subjective tests will tell us how sensitive the instrument should be. Then the objective readings from the instrument give an indication of how acceptable a signal is in respect of that characteristic.
The sense we call hearing results from acoustic, mechanical, hydraulic, nervous and mental processes in the ear/brain combination, leading to the term psychoacoustics. It’s only possible briefly to introduce the subject here. The interested reader is referred to Moore for an excellent treatment.

FIG. 7 The structure of the human ear. See text for details.

FIG. 8 The malleus tensions the tympanic membrane into a conical shape. The
ossicles provide an impedance-transforming lever system between the tympanic
membrane and the oval window.
FIG. 7 shows that the structure of the ear is traditionally divided into the outer, middle and inner ears. The outer ear works at low impedance, the inner ear works at high impedance, and the middle ear is an impedance matching device. The visible part of the outer ear is called the pinna which plays a subtle role in determining the direction of arrival of sound at high frequencies. It’s too small to have any effect at low frequencies. Incident sound enters the auditory canal or meatus. The pipe-like meatus causes a small resonance at around 4 kHz. Sound vibrates the eardrum or tympanic membrane which seals the outer ear from the middle ear. The inner ear or cochlea works by sound travelling though a fluid. Sound enters the cochlea via a membrane called the oval window.
If airborne sound were to be incident on the oval window directly, the serious impedance mismatch would cause most of the sound to be reflected. The middle ear remedies that mismatch by providing a mechanical advantage. The tympanic membrane is linked to the oval window by three bones known as ossicles which act as a lever system such that a large displacement of the tympanic membrane results in a smaller displacement of the oval window but with greater force. FIG. 8 shows that the malleus applies a tension to the tympanic membrane rendering it conical in shape. The malleus and the incus are firmly joined together to form a lever. The incus acts upon the stapes through a spherical joint. As the area of the tympanic membrane is greater than that of the oval window, there is a further multiplication of the available force. Consequently small pressures over the large area of the tympanic membrane are converted to high pressures over the small area of the oval window.
The middle ear is normally sealed, but ambient pressure changes will cause static pressure on the tympanic membrane which is painful. The pressure is relieved by the Eustachian tube which opens involuntarily while swallowing. The Eustachian tubes open into the cavities of the head and must normally be closed to avoid one's own speech appearing deafeningly loud.
The ossicles are located by minute muscles which are normally relaxed.
However, the middle ear reflex is an involuntary tightening of the tensor tympani and stapedius muscles which heavily damp the ability of the tympanic membrane and the stapes to transmit sound by about 12 dB at frequencies below 1 kHz. The main function of this reflex is to reduce the audibility of one's own speech. However, loud sounds will also trigger this reflex which takes some 60-120ms to occur, too late to protect against transients such as gunfire.
7. The cochlea
The cochlea, shown in FIG. 9(a), is a tapering spiral cavity within bony walls which is filled with fluid. The widest part, near the oval window, is called the base and the distant end is the apex. FIG. 9(b) shows that the cochlea is divided lengthwise into three volumes by Reissner's membrane and the basilar membrane. The scala vestibuli and the scala tympani are connected by a small aperture at the apex of the cochlea known as the helicotrema. Vibrations from the stapes are transferred to the oval window and become fluid pressure variations which are relieved by the flexing of the round window. Effectively the basilar membrane is in series with the fluid motion and is driven by it except at very low frequencies where the fluid flows through the helicotrema, bypassing the basilar membrane.
The vibration of the basilar membrane is sensed by the organ of Corti which runs along the centre of the cochlea. The organ of Corti is active in that it contains elements which can generate vibration as well as sense it.
These are connected in a regenerative fashion so that the Q factor, or frequency selectivity of the ear, is higher than it would otherwise be. The deflection of hair cells in the organ of Corti triggers nerve firings and these signals are conducted to the brain by the auditory nerve. Some of these signals reflect the time domain, particularly during the transients with which most real sounds begin and also at low frequencies. During continuous sounds, the basilar membrane is also capable of performing frequency analysis.

FIG. 9 (a) The cochlea is a tapering spiral cavity. (b) The cross-section
of the cavity is divided by Reissner's membrane and the basilar membrane. (c)
The basilar membrane tapers so its resonant frequency changes along its length.
FIG. 9(c) shows that the basilar membrane is not uniform, but tapers in width and varies in thickness in the opposite sense to the taper of the cochlea. The part of the basilar membrane which resonates as a result of an applied sound is a function of the frequency. High frequencies cause resonance near to the oval window, whereas low frequencies cause resonances further away. More precisely the distance from the apex where the maximum resonance occurs is a logarithmic function of the frequency. Consequently tones spaced apart in octave steps will excite evenly spaced resonances in the basilar membrane. The prediction of resonance at a particular location on the membrane is called place theory.
Essentially the basilar membrane is a mechanical frequency analyzer. A knowledge of the way it operates is essential to an understanding of musical phenomena such as pitch discrimination, timbre, consonance and dissonance and to auditory phenomena such as critical bands, masking and the precedence effect.
Nerve firings are not a perfect analog of the basilar membrane motion.
On continuous tones a nerve firing appears to occur at a constant phase relationship to the basilar vibration, a phenomenon called phase locking, but firings don’t necessarily occur on every cycle. At higher frequencies firings are intermittent, yet each is in the same phase relationship.
The resonant behavior of the basilar membrane is not observed at the lowest audible frequencies below 50Hz. The pattern of vibration does not appear to change with frequency and it’s possible that the frequency is low enough to be measured directly from the rate of nerve firings.
8. Mental processes
The nerve impulses are processed in specific areas of the brain which appear to have evolved at different times to provide different types of information. The time domain response works quickly, primarily aiding the direction-sensing mechanism and is older in evolutionary terms. The frequency domain response works more slowly, aiding the determination of pitch and timbre and evolved later, presumably after speech evolved.
The earliest use of hearing was as a survival mechanism to augment vision. The most important aspect of the hearing mechanism was the ability to determine the location of the sound source. FIG. 10 shows that the brain can examine several possible differences between the signals reaching the two ears. At (a) a phase shift will be apparent. At (b) the distant ear is shaded by the head resulting in a different frequency response compared to the nearer ear. At (c) a transient sound arrives later at the more distant ear. The inter-aural phase, delay and level mechanisms vary in their effectiveness depending on the nature of the sound to be located. At some point a fuzzy logic decision has to be made as to how the information from these different mechanisms will be weighted.
There will be considerable variation with frequency in the phase shift between the ears. At a low frequency such as 30Hz, the wavelength is around 11.5 meters and so this mechanism must be quite weak at low frequencies. At high frequencies the ear spacing is many wavelengths producing a confusing and complex phase relationship. This suggests a frequency limit of around 1500Hz which has been confirmed by experiment.

FIG. 10 Having two spaced ears is cool. (a) Off-centre sounds result in phase
difference. (b) Distant ear is shaded by head producing loss of high frequencies.
(c) Distant ear detects transient later.

FIG. 11 Real acoustic event produces a pressure step. Initial step is used
for spatial location, equalization time signifies size of source.
At low and middle frequencies sound will diffract round the head sufficiently well that there will be no significant difference between the level at the two ears. Only at high frequencies does sound become directional enough for the head to shade the distant ear causing what is called an inter-aural intensity difference (IID).
Phase differences are only useful at low frequencies and shading only works at high frequencies. Fortunately real-world sounds are timbral or broadband and often contain transients. Timbral, broadband and transient sounds differ from tones in that they contain many different frequencies.
A transient has an unique aperiodic waveform which, as FIG. 10(c) shows, suffers no ambiguity in the assessment of inter-aural delay (IAD) between two versions. Note that a one-degree change in sound location causes a IAD of around 10 microseconds. The smallest detectable IAD is a remarkable 6 microseconds. This should be the criterion for spatial reproduction accuracy.
A timbral waveform is periodic at the fundamental frequency but the presence of harmonics means that a greater number of nerve firings can be compared between the two ears. As the statistical deviation of nerve firings with respect to the incoming waveform is about 100 microseconds the only way in which an IAD of 6 microseconds can be resolved is if the timing of many nerve firings is correlated in some way in the brain.
Transient noises produce a one-off pressure step whose source is accurately and instinctively located. FIG. 11 shows an idealized transient pressure waveform following an acoustic event. Only the initial transient pressure change is required for location. The time of arrival of the transient at the two ears will be different and will locate the source laterally within a processing delay of around a millisecond.
Following the event which generated the transient, the air pressure equalizes. The time taken for this equalization varies and allows the listener to establish the likely size of the sound source. The larger the source, the longer the pressure-equalization time. Only after this does the frequency analysis mechanism tell anything about the pitch and timbre of the sound.
The above results suggest that anything in a sound reproduction system which impairs the reproduction of a transient pressure change will damage localization and the assessment of the pressure-equalization time. Clearly in an audio system which claims to offer any degree of precision, every component must be able to reproduce transients accurately and must have at least a minimum phase characteristic if it cannot be phase linear. In this respect digital audio represents a distinct technical performance advantage although much of this is lost in poor transducer design, especially in loudspeakers.
9. Level and loudness
At its best, the ear can detect a sound pressure variation of only 2 _ 10-5 Pascals r.m.s. and so this figure is used as the reference against which sound pressure level (SPL) is measured. The sensation of loudness is a logarithmic function of SPL and consequently a logarithmic unit, the deciBel, was adopted for audio measurement. The deciBel is explained in detail below.
The dynamic range of the ear exceeds 130 dB, but at the extremes of this range, the ear is either straining to hear or is in pain. Neither of these cases can be described as pleasurable or entertaining, and it’s hardly necessary to produce audio of this dynamic range since, among other things, the consumer is unlikely to have anywhere sufficiently quiet to listen to it. On the other hand, extended listening to music whose dynamic range has been excessively compressed is fatiguing.
The frequency response of the ear is not at all uniform and it also changes with SPL. The subjective response to level is called loudness and is measured in phons. The phon scale is defined to coincide with the SPL scale at 1 kHz, but at other frequencies the phon scale deviates because it displays the actual SPLs judged by a human subject to be equally loud as a given level at 1 kHz. FIG. 12 shows the so-called equal loudness contours which were originally measured by Fletcher and Munson and subsequently by Robinson and Dadson. Note the irregularities caused by resonances in the meatus at about 4 kHz and 13 kHz.
Usually, people's ears are at their most sensitive between about 2 kHz and 5 kHz, and although some people can detect 20 kHz at high level, there is much evidence to suggest that most listeners cannot tell if the upper frequency limit of sound is 20 kHz or 16 kHz. For a long time it was thought that frequencies below about 40Hz were unimportant, but it’s now clear that reproduction of frequencies down to 20Hz improves reality and ambience. The generally accepted frequency range for high-quality audio is 20Hz to 20 000Hz, although for broadcasting an upper limit of 15 000Hz is often applied.
The most dramatic effect of the curves of FIG. 12 is that the bass content of reproduced sound is disproportionately reduced as the level is turned down. This would suggest that if a sufficiently powerful yet high quality reproduction system is available the correct tonal balance when playing a good recording can be obtained simply by setting the volume control to the correct level. This is indeed the case. A further consideration is that many musical instruments as well as the human voice change timbre with level and there is only one level which sounds correct for the timbre.

FIG. 12 Contours of equal loudness showing that the frequency response of
the ear is highly level dependent (solid line, age 20; dashed line, age 60).

FIG. 13 The basilar membrane symbolically uncoiled. (a) Single frequency
causes the vibration envelope shown. (b) Changing the frequency moves the peak
of the envelope.
Audio systems with a more modest specification would have to resort to the use of tone controls to achieve a better tonal balance at lower SPL.
A loudness control is one where the tone controls are automatically invoked as the volume is reduced. Although well meant, loudness controls seldom compensate accurately because they must know the original level at which the material was meant to be reproduced as well as the actual level in use. The equalization applied would have to be the difference between the equal loudness curves at the two levels.
There is no standard linking the signal level on a recording with the SPL at the microphone. The SPL resulting from a given signal level leaving a loudness control depends upon the sensitivity of the power amplifier and the loudspeakers and the acoustics of the listening room.
Consequently unless set up for a particular installation, loudness controls are doomed to be inaccurate and are eschewed on high-quality equipment.
A further consequence of level-dependent hearing response is that recordings which are mixed at an excessively high level will appear bass light when played back at a normal level. Such recordings are more a product of self-indulgence than professionalism.
Loudness is a subjective reaction and is almost impossible to measure.
In addition to the level-dependent frequency response problem, the listener uses the sound not for its own sake but to draw some conclusion about the source. For example, most people hearing a distant motorcycle will describe it as being loud. Clearly at the source, it’s loud, but the listener has compensated for the distance.
The best that can be done is to make some compensation for the level dependent response using weighting curves. Ideally there should be many, but in practice the A, B and C weightings were chosen where the A curve is based on the 40-phon response. The measured level after such a filter is in units of dBA. The A curve is almost always used because it most nearly relates to the annoyance factor of distant noise sources.
10. Frequency discrimination
FIG. 13 shows an uncoiled basilar membrane with the apex on the left so that the usual logarithmic frequency scale can be applied. The envelope of displacement of the basilar membrane is shown for a single frequency at (a). The vibration of the membrane in sympathy with a single frequency cannot be localized to an infinitely small area, and nearby areas are forced to vibrate at the same frequency with an amplitude that decreases with distance. Note that the envelope is asymmetrical because the membrane is tapering and because of frequency-dependent losses in the propagation of vibrational energy down the cochlea. If the frequency is changed, as in (b), the position of maximum displacement will also change. As the basilar membrane is continuous, the position of maximum displacement is infinitely variable allowing extremely good pitch discrimination of about one twelfth of a semitone which is determined by the spacing of hair cells.
In the presence of a complex spectrum, the finite width of the vibration envelope means that the ear fails to register energy in some bands when there is more energy in a nearby band. Within those areas, other frequencies are mechanically excluded because their amplitude is insufficient to dominate the local vibration of the membrane. Thus the Q factor of the membrane is responsible for the degree of auditory masking, defined as the decreased audibility of one sound in the presence of another.

FIG. 14 The critical bandwidth changes with SPL.

FIG. 15 Impulse response of the ear showing slow attack and decay due to
resonant behavior.

FIG. 16 Perceived level of tone burst rises with duration as resonance builds
up.
11. Critical bands
The term used in psychoacoustics to describe the finite width of the vibration envelope is critical bandwidth. Critical bands were first described by Fletcher.
The envelope of basilar vibration is a complicated function.
It’s clear from the mechanism that the area of the membrane involved will increase as the sound level rises. FIG. 14 shows the bandwidth as a function of level.
As will be seen in Section 3, transform theory teaches that the higher the frequency resolution of a transform, the worse the time accuracy. As the basilar membrane has finite frequency resolution measured in the width of a critical band, it follows that it must have finite time resolution.
This also follows from the fact that the membrane is resonant, taking time to start and stop vibrating in response to a stimulus. There are many examples of this. FIG. 15 shows the impulse response. FIG. 16 shows the perceived loudness of a tone burst increases with duration up to about 200ms due to the finite response time.
The ear has evolved to offer intelligibility in reverberant environments which it does by averaging all received energy over a period of about 30ms. Reflected sound which arrives within this time is integrated to produce a louder sensation, whereas reflected sound which arrives after that time can be temporally discriminated and is perceived as an echo.
Microphones have no such ability, which is why acoustic treatment is often needed in areas where microphones are used.
A further example of the finite time discrimination of the ear is the fact that short interruptions to a continuous tone are difficult to detect. Finite time resolution means that masking can take place even when the masking tone begins after and ceases before the masked sound. This is referred to as forward and backward masking.

FIG. 17 Effective rectangular bandwidth of critical band is much wider than
the resolution of the pitch discrimination mechanism.
As the vibration envelope is such a complicated shape, Moore and Glasberg have proposed the concept of equivalent rectangular bandwidth to simplify matters. The ERB is the bandwidth of a rectangular filter which passes the same power as a critical band. FIG. 17(a) shows the expression they have derived linking the ERB with frequency. This is plotted in (b) where it will be seen that one third of an octave is a good approximation. This is about thirty times broader than the pitch discrimination also shown in (b).
Some treatments of human hearing liken the basilar membrane to a bank of fixed filters each of which is the width of a critical band. The frequency response of such a filter can be deduced from the envelope of basilar displacement as has been done in FIG. 18. The fact that no agreement has been reached on the number of such filters should alert the suspicions of the reader. A third octave filter bank model cannot explain pitch discrimination some thirty times better. The response of the basilar membrane is centered upon the input frequency and no fixed filter can do this. However, the most worrying aspect of the fixed filter model is that according to FIG. 18(b) a single tone would cause a response in several bands which would be interpreted as several tones. This is at variance with reality. Far from masking higher frequencies, we appear to be creating them!

FIG. 18 (a) If the ear behaved like a fixed filter bank the filter response
could be derived as shown here. (b) This theory does not hold because a single
tone would cause response in several bands.

FIG. 19 (a) Result of adding two sine waves of similar frequency. (b) Spectrum
of (a) to infinite accuracy. (c) With finite accuracy only a single frequency
is distinguished whose amplitude changes with the envelope of (a) giving rise
to beats.
This author prefers to keep in mind how the basilar membrane is actually vibrating is response to an input spectrum. If a mathematical model of the ear is required, then it has to be described as performing a finite resolution continuous frequency transform.
12. Beats
FIG. 19 shows an electrical signal (a) in which two equal sine waves of nearly the same frequency have been linearly added together. Note that the envelope of the signal varies as the two waves move in and out of phase. Clearly the frequency transform calculated to infinite accuracy is that shown at (b). The two amplitudes are constant and there is no evidence of the envelope modulation. However, such a measurement requires an infinite time. When a shorter time is available, the frequency discrimination of the transform falls and the bands in which energy is detected become broader.

FIG. 20 Perception of two-tone signal as frequency difference changes.
When the frequency discrimination is too wide to distinguish the two tones as in (c), the result is that they are registered as a single tone. The amplitude of the single tone will change from one measurement to the next because the envelope is being measured. The rate at which the envelope amplitude changes is called a beat frequency which is not actually present in the input signal. Beats are an artifact of finite frequency resolution transforms. The fact that human hearing produces beats from pairs of tones proves that it has finite resolution.
Measurement of when beats occur allows measurement of critical bandwidth. FIG. 20 shows the results of human perception of a two tone signal as the frequency dF difference changes. When dF is zero, described musically as unison, only a single note is heard. As dF increases, beats are heard, yet only a single note is perceived. The limited frequency resolution of the basilar membrane has fused the two tones together. As dF increases further, the sensation of beats ceases at 12-15Hz and is replaced by a sensation of roughness or dissonance. The roughness is due to parts of the basilar membrane being unable to decide the frequency at which to vibrate. The regenerative effect may well become confused under such conditions. The roughness which persists until dF has reached the critical bandwidth beyond which two separate tones will be heard because there are now two discrete basilar resonances. In fact this is the definition of critical bandwidth.
13. Music and the ear

FIG. 21 Spectrum of a real instrument with respect to critical bandwidth.
High harmonics can fall in the same critical band and cause dissonance.
The characteristics of the ear, especially critical bandwidth, are responsible for the way music has evolved. Beats are used extensively in music.
When tuning a pair of instruments together, a small tuning error will result in beats when both play the same nominal note. In certain pipe organs, pairs of pipes are sounded together with a carefully adjusted pitch error which results in a pleasing tremolo effect.
With certain exceptions, music is intended to be pleasing and so dissonance is avoided. Two notes which sound together in a pleasing manner are described as harmonious or consonant. Two sine waves appear consonant if they separated by a critical bandwidth because the roughness of FIG. 20 is avoided, but real musical instruments produce a series of harmonics in addition to the fundamental.
FIG. 21 shows the spectrum of a harmonically rich instrument. The fundamental and the first few harmonics are separated by more than a critical band, but from the seventh harmonic more than one harmonic will be in one band and it’s possible for dissonance to occur. Musical instruments have evolved to avoid the production of seventh and higher harmonics. Violins and pianos are played or designed to excite the strings at a node of the seventh harmonic to suppress this dissonance.
Harmonic distortion in audio equipment is easily detected even in minute quantities because the first few harmonics fall in non-overlapping critical bands. The sensitivity of the ear to third harmonic distortion probably deserves more attention in audio equipment than the fidelity of the dynamic range or frequency response. The ear is even more sensitive to anharmonic distortion which can be generated in poor-quality ADCs.
This topic will be considered in Section 4.
When two harmonically rich notes are sounded together, the harmonics will fall within the same critical band and cause dissonance unless the fundamentals have one of a limited number of simple relationships which makes the harmonics fuse. Clearly an octave relationship is perfect.
FIG. 22 shows some examples. In (a) two notes with the ratio (interval) 3:2 are considered. The harmonics are either widely separated or fused and the combined result is highly consonant. The interval of 3:2 is known to musicians as a perfect fifth. In (b) the ratio is 4:3. All harmonics are either at least a third of an octave apart or are fused. This relationship is known as a perfect fourth. The degree of dissonance over the range from 1:1 to 2:1 (unison to octave) was investigated by Helmholtz and is shown in (c). Note that the dissonance rises at both ends where the fundamentals are within a critical bandwidth of one another.
Dissonances in the centre of the scale are where some harmonics lie within a critical bandwidth of one another. Troughs in the curve indicate areas of consonance. Many of the troughs are not very deep, indicating that the consonance is not perfect. This is because of the effect shown in FIG. 21 in which high harmonics get closer together with respect to critical bandwidth. When the fundamentals are closer together, the harmonics will become dissonant at a lower frequency, reducing the consonance. FIG. 22 also shows the musical terms used to describe the consonant intervals.

FIG. 22 (a) Perfect fifth with a frequency ratio of 3:2 is consonant because
harmonics are either in different critical bands or are fused. (b) Perfect
fourth achieves the same result with 4:3 frequency ratio. (c) Degree of dissonance
over range from 1:1 to 2:1.
It’s clear from FIG. 22(c) that the notes of the musical scale have empirically been established to allow the maximum consonance with pairs of notes and chords. Early instruments were tuned to the just diatonic scale in exactly this way. Unfortunately the just diatonic scale does not allow changes of key because the notes are not evenly spaced. A key change is where the frequency of every note in a piece of music is multiplied by a constant, often to bring the accompaniment within the range of a singer. In continuously tuned instruments such as the violin and the trombone this is easy, but with fretted or keyboard instruments such as a piano there is a problem.
The equal-tempered scale is a compromise between consonance and key changing. The octave is divided into twelve equal intervals called tempered semitones. On a keyboard, seven of the keys are white and produce notes very close to those of the just diatonic scale, and five of the keys are black. Music can be transposed in semitone steps by using the black keys.
FIG. 23 shows an example of transposition where a scale is played in several keys.

FIG. 23 With a suitably tempered octave, scales can be played in different
keys.
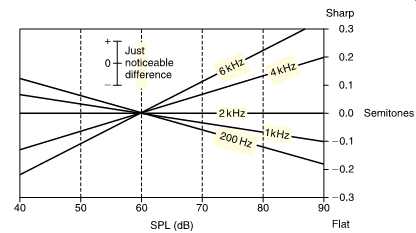
FIG. 24 Pitch sensation is a function of level.

FIG. 25 (a) Harmonic structure of rich sound. (b) Even harmonic predominance.
(c) Odd harmonic predominance. Pitch perception appears independent of harmonic
structure.