AC-3 Exponent Strategies and Bit Allocation
For improved bit efficiency, the differential exponents are combined into groups in the audio block. One, two, or four mantissas can use the same exponent. These groupings are known as D15, D25, or D45 modes, respectively, and are referred to as exponent strategies. The number of grouped differential exponents placed in the audio block for a channel depends on the exponent strategy and the frequency bandwidth of that channel. The number of exponents in each group depends only on the exponent strategy, which is based on the need to minimize audibility of quantization noise. In D15 exponent coding of the spectral envelope (2.33 bits per exponent), groups of three differentials are coded in a 7-bit word; D15 provides fine frequency resolution at the expense of temporal resolution.
It is used when the audio signal envelope is relatively constant over many audio blocks. Because D15 is conveyed when the spectrum is stable, the estimate is coded only occasionally, for example, once every six blocks (32 ms) yielding 0.39 bits per audio sample.
The spectral estimate must be updated more frequently when transient signals are coded. The spectral envelope must follow the time variations in the signal; this estimate is coded with less frequency resolution. Two methods are used. D25 provides moderate frequency resolution and moderate temporal resolution. Coefficients are shared across frequency pairs. A delta is coded for every other frequency coefficient; the data rate is 1.17 bits per exponent. D25 is used when the spectrum is stable over two to three blocks, and then significantly changes. In the D45 coding, one delta is coded for every four coefficients; the data rate is 0.58 bits per exponent. D45 provides high temporal resolution and low frequency resolution. It is used when transients occur within single audio blocks. The encoder selects the exponent coding method (D15, D25, D45, or REUSE) for every audio block and places this in a 2-bit exponent strategy field. Because the exponent selection is coded in the bitstream, the decoder tracks the results of any encoder methodology. Examples of the D15, D25, and D45 modes are shown in FIG. 22.
Exponents can also be shared across time. Signals may be stationary for longer than a 512-sample block and have similar spectral content over many blocks. Thus, exponents can be reused for subsequent blocks. In most cases, D15 is coded in the first block in a frame, and reused for the next five blocks. This can reduce the exponent data rate by a factor of 6, to 0.10 bits per exponent.
Most encoders use a forward-adaptive psychoacoustics model and bit allocation that analyzes the signal spectrum and quantizes mantissa values and sends them to the decoder; all modeling and allocation is done in the encoder. In contrast, the AC-3 encoder contains a forward backward adaptive psychoacoustics model that determines the masked threshold and quantization, and the decoder also contains the core backward-adaptive model.
This reduces the amount of bit allocation information that must be conveyed. The encoder bases bit allocation on exponent values, and because the decoder receives the exponent values, it can backward-adaptively re-compute the corresponding bit allocation. The approach allows overall lower bit rates, at the expense of increased decoder complexity. Also, this limits the ability to revise the psychoacoustic model in the encoder while retaining compatibility with existing decoders. This is addressed with a parametric model, and by providing for a forward adaptive delta correction factor.
In the encoder, the forward-adaptive model uses an iterative rate control loop to determine the model's parameters defining offsets of maskers from a masking contour. These are used by the backward-adaptive model, along with quantized spectral envelope information, to estimate the masked threshold. The perceptual model's parameters and an optional forward-adaptive delta bit allocation that can adjust the masking thresholds are conveyed to the decoder.
FIG. 22 Three examples of spectral envelope (exponent) coding strategies used in the AC-3 codec. A. D15 mode coding for a triangle signal. B. D25 mode coding for a triangle signal. C. D45 mode coding for a castanet signal. (Todd et al., 1994)
The encoder's bit allocation delta parameter can be used to upgrade the encoder's functionality. Future encoders could employ two perceptual models, the original version and an improved version, and the encoder could convey a masking level adjustment.
The bit allocation routine analyzes the spectral envelope of the audio signal according to masking criteria to determine the number of bits to assign to each mantissa.
Ideally, allocation is calculated so that the SNR for quantized mantissas is greater than or equal to the SMR.
There are no pre-assigned mantissa or exponent bits; assignment is performed globally on all channels from a bit pool. The routine interacts with the parametric perceptual model to estimate audible and inaudible spectral components. The estimated noise level threshold is computed for 50 bands of nonuniform bandwidth (approximately 1.6 octaves). The bit allocation for each mantissa is determined by a lookup table based on the difference between the input signal power spectral density (psd) along a fine-grain uniform frequency scale, and estimated noise level threshold along a banded coarse grain frequency scale. The routine considers the decoded spectral envelope to be the power spectral density of the signal. This signal is effectively convolved, using two IIR filters for the two-slope spreading function, with a simplified spreading function that represents the ear's masking response. The spreading function is approximated by two masking curves: a fast-decaying upward curve and slow decaying upward curve, which is offset downward in level.
The curves are referred to as a fast leak and slow leak.
Convolution is performed starting at the lowest frequency psd. Each new psd is compared to current leak values and judged to be significant or not; this yields the predicted masking value for each band. The shape of the spreading function is conveyed to the decoder by four parameters.
This predicted curve is compared to a hearing threshold, and the larger of the values is used at each frequency point to yield a global masking curve. The resulting predicted masking curve is subtracted from the original unbanded psd to determine the SNR value for each transform coefficient. These are used to quantize each coefficient mantissa from 0 to 16 bits. Odd-symmetric quantization (the mantissa range is divided by an odd number of steps that are equal in width and symmetric about zero) is used for all low-precision quantizer levels (3-, 5-, 7-, 11-, 15-level) to avoid biases in coding, and even-symmetric quantization (the first step is 50% shorter and the last step is 50% longer than the rest) is used for all other quantization levels (from 32-level through 65,536-level).
Bits are taken iteratively from a common bit pool available to all channels. Mantissa quantization is adjusted to use the available bit rate. The effect of interchannel masking is relatively slight. To minimize audible quantization noise at low frequencies where frequency resolution is relatively low, the noise from coefficients is examined and bits are iteratively added to lower noise where necessary. Quantized mantissas are scaled and offset. Subtractive dither is optionally employed when zero bits are allocated to the mantissa. A pseudo-random number generator can be used. A mode bit indicates when dither is used and provides synchronization to the decoder's subtractive dither circuit. In addition, the carrier portion of high-frequency localization information is removed, and the envelope is coded instead; high frequency multichannel carrier content may be combined into a coupling channel.
AC-3 Multichannel Coding
One of the hallmarks of AC-3 coding is its ability to efficiently code an ensemble of multiple channels to a single low bit-rate bitstream. To achieve greater bit efficiency, the encoder may use channel coupling and rematrixing on selective frequencies while preserving perceptual spatial accuracy. Channel coupling, based on intensity stereo coding, combines the high-frequency content of two or more channels into one coupling channel.
The combined coupling channel, along with coupling coordinates, the quantized power spectral ratios between each channel's original signal and the coupled channel, are conveyed for decoding and reconstructing the original energy envelopes. Coupling may be performed at low bit rates, when signal conditions exceed the bit rate. It efficiently (but perhaps not transparently) codes a multichannel signal, taking into account high-frequency directionality limitations in human hearing, without reducing audio bandwidth. Above 3 kHz, the ear is unable to distinguish the fine temporal structure of high-frequency waveforms and instead relies on the envelope energy of the sounds. In other words, at high frequencies, we are not sensitive to phase, but only to amplitude. Directionality is determined by the interaural time delay of the envelope and by perceived frequency response based on head shadowing. As a result, the ear cannot independently detect the direction of two high-frequency sounds that are close in frequency.
Coupling can yield significant bit-rate reduction. As Steve Vernon points out, given the critical band resolution, high-frequency mantissa magnitudes do not need to be accurately coded for individual frequency bins, as long as the overall signal energy in each critical band is correct.
Because 85% of transform coefficients are above 3 kHz, large amounts of error are acceptable in high-frequency bands.
The AC-3 codec can couple channels at high frequencies; care is taken to avoid phase cancellation of the common channels. The coupling strategy is determined wholly in the encoder. Coupling coordinates for each individual channel are used to code the ratio of original signal power in a band to the coupling channel power in each band. Coupling channels are encoded in the same way as individual channels with a spectral envelope comprising exponents and mantissas. Frequencies below a certain coupling frequency (a range of 3 kHz to 20 kHz is possible, with 10 kHz being typical) are encoded as individual channels, and encoded as coupling coordinates above the coupling frequency. With a 10-kHz coupling frequency, the data rate for exponents and mantissas is nearly halved. Half of the exponents and mantissas for each coupled channel are discarded. Only the exponents and mantissas for the coupling channel, and scale factors, are conveyed.
FIG. 23A shows an example of channel coupling of three channels. Phase is adjusted to prevent cancellation when summing channels. The monaural coupled channel is created by summing the input coupled-channel spectral coefficients above the coupling frequency. The signal energy in each critical band of the input channels and coupled channel are computed and used to determine coupling coordinate scale factors. The energy in each band of each coupled channel is divided by the energy in each corresponding band of the coupling channel. The scale factors thus represent the amount that the decoder will scale the coupling-channel bands to re-create bands of the original energy. The dynamic range of the scaling factors may range from -132 to +18 dB with a resolution between 0.28 dB to 0.53 dB. One to 18 frequency bands may be used, with 14 bands being typical. During decoding, individual channel-coupling coordinates are multiplied by the coupling-channel coefficients to regenerate individual high-frequency coefficients. FIG. 23B shows how three coupled channels are decoded.
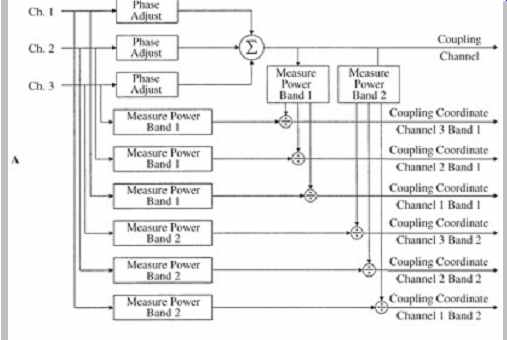

FIG. 23 The AC-3 codec can couple audio channels at high frequencies.
In this illustration, three channels are coupled to form one coupling channel.
A. Encode coupling process. B. Decode coupling process. (Fielder, 1996)
The encoder may also use rematrixing coding, similar to M/S coding, to exploit the correlation between channel pairs. Rather than code the spectra of right and left (R, L) channels independently, the sum and difference (R, L) is coded. For example, when the R and L channels are identical, no bits are allocated to the R channel.
Rematrixing is applied selectively to up to four frequency regions; the regions are based on coupling information.
Rematrixing is not used in coupling channels but can be used simultaneously with coupling. If used with coupling, the rematrixing frequency region ends at the start of the coupling region. Rematrixing coding is only used in 2/0 channel mode, and is compatible with Dolby Pro Logic and other matrix systems.
If matrixing is not used and a decoded perceptually coded monaural signal is played through a matrix decoder, small differences in quantization noise between the two channels could cause the matrix system to derive a surround channel from the noise differences between channels, and thus direct unmasked quantization noise to the surround channels. Moreover, the noise will be modulated by the center-channel signal, further increasing audibility. Rematrixing ensures that when the input signals are highly correlated, the quantization noise is also highly correlated. Thus, when a rematrixed two-channel AC-3 signal is played through a matrix system, quantization noise will not be unmasked.
AC-3 Bitstream and Decoder
Data in an AC-3 bitstream is contained in frames, as shown in FIG. 24. Each frame is an independently encoded entity. A frame contains a synchronization information (SI ) header, bitstream information (BSI ) header, 32 milliseconds of audio data as quantized frequency coefficients, auxiliary field, and CRCC error detection data.
The frame period is 32 milliseconds at a 48-kHz sampling frequency. The SI field contains a 16-bit synchronization word, 2-bit sampling rate code, and 6-bit frame size code.
The BSI field describes the audio data with information such as coding mode, timecode, copyright, normalized dialogue level, and language code. Audio blocks are variable length, but six transform blocks, with 256 samples per block (1536 in total), must fit in one frame. Audio blocks mainly comprise quantized mantissas, exponent strategy, differentially coded exponents, coupling data, rematrixing data, block switch flags, dither flags, and bit allocation parameters. Each block contains data for all coded channels. A frame holds a constant number of bits based on the bit rate. However, audio block boundaries are not fixed. This allows the encoder to globally allocate bitstream resources where needed.

FIG. 24 Structure of the AC-3 bitstream showing blocks in an audio frame.
( Vernon, 1999)
One 16-bit CRCC word is contained at the end of each frame, and an additional 16-bit CRCC word may be optionally placed in the SI header. In each case, the generating polynomial is x16 +x15 + x2 + 1. Error detection and the response to errors vary in different AC-3 applications. Error concealment can be used in which a previous audio segment is repeated to cover a burst error.
The decoder does not decode erroneous data; this could lead to invalid bit allocation. The first block always contains a complete refresh of all decoding information. Unused block areas may be used for auxiliary data. Audio data is placed in the bitstream so that the decoder can begin to output a signal before starting to decode the second block.
This reduces the memory requirements in the decoder because it does not need to store parameters for more than one block at a time.
One or more AC-3 streams may be conveyed in an MPEG-2 transport stream as defined in the ISO/IEC 13818-1 standard. The stream is packetized as PES packets. It is not necessary to unambiguously indicate that a stream is AC-3. The MPEG-2 standard does not contain codes to indicate an AC-3 stream. One or more AC-3 streams may also be conveyed in an AES3 or IEC958 interface. Each AC-3 frame represents 1536 encoded audio samples (divided into 6 blocks of 256 samples each). AC-3 frame boundaries occur at a frequency of exactly once every 1536 IEC958 frames.
The decoder receives data frames; it can accept a continuous data stream at the nominal bit rate, or chunks of data burst at a high rate. The decoder synchronizes the data and performs error correction as necessary. The decoder contains the same backward-adaptive perceptual model as the encoder and uses the spectral envelope to perform backward-adaptive bit allocation. The quantized mantissas are denormalized by their exponents. However, using delta bit allocation values, the encoder can change model parameters and thus modify the threshold calculations in the decoder. As necessary, decoupling is performed by reconstructing the high-frequency section (exponents and mantissas) of each coupled channel. The common coupling-channel coefficients are multiplied by the coupling coordinates for the individual channel. As necessary, dynamic range compression and other processing is performed on blocks of audio data.
Coefficients are returned to fixed-point representation, dither is subtracted, and carrier and envelope information is reconstructed. The inverse TDAC transform, window, and overlap operations produce data that is buffered prior to outputting continuous PCM data. Blocks of 256 coefficients are transformed to a block of 512 time samples; with overlap-and-add, 256 samples are output.
LFE data is padded with zeros before the inverse transform so the output sampling frequency is compatible with the other channels. Multiple channels are restored and dynamic range parameters are applied.
When mantissa values are quantized to 0 bits, the decoder can substitute a dither value. Dither flags placed by the encoder determine when dither substitution is used.
At very low data rates, the dither is a closer approximation to the original unquantized signal in that frequency range than entirely removing the signal would be. Also, dither is preferred over the potentially audible modulation in cases where a low-level component might appear on and off in successive blocks. Dither substitution is not used for short transform blocks (when a soft-signal block is followed by a loud-signal block) because the interleaved small and large values in the coefficient array and their exponents can cause the dither signal to be scaled to a higher, too-audible level in the short block.
The decoder can perform downmixing that is required when the number of output channels is less than the number of coded channels. In this way, the full multichannel program can be reproduced over fewer channels. The decoder decodes channels and routes them to output channels using downmix scale factors supplied by the encoder that set each channel's relative level. Downmixes can be sent to eight different output configurations. There are two 2-channel modes, a stereo or a matrix surround mode; the LFE is not included in these downmixes.
As noted, the AC-3 codec can code original content in L/R matrix surround sound formats, two-channel stereo, or monaural form. Conversely, all of these formats can be downmixed at the decoder from a multichannel AC-3 bitstream, using information in the BSI header. A decoder may also use metadata (entered during encoding) for volume normalization. Program material from different sources and using different reference volume levels can be replayed at a consistent level. Because of the importance of dialogue, its level is used as the reference; program levels are adjusted so that their long-term averaged dialogue levels are the same during playback. A parameter called dialnorm can control relative volume level of dialogue (or other audio content) with values from -1 dBFS to -31 dBFS in 1-dB steps. The value does not measure attenuation directly but rather the LAeq value of the content.
Program material with a dialogue level higher than a dial norm setting is normalized downward to that setting.
Metadata also controls the dynamic range of playback (dynrng). The ATSC DTV standard sets the normalized dialogue level at -31 dBFS LA eq below digital full scale to represent optimal dialogue normalization. The decoder can thus maintain intelligibility in a variety of playback content.
For material other than speech, more subjective settings are used. Dynamic range control compresses the output at the decoder; this accounts for different listening conditions with background noise levels. Because this metadata may be included in every block, the control words may occur every 5.3 ms at a 48-kHz sampling rate. A smoothing effect is used between blocks to minimize audibility of gain changes. Not all decoders allow the user to manually access functions such as dynamic range control.
Algorithms such as AC-3 can be executed on general purpose processors, or high performance dedicated processors. Both floating- and fixed-point processors are used; floating-point processors are generally more expensive, but can execute AC-3 in fewer cycles with good fidelity. However, the higher cost as well as relatively greater memory requirements may make fixed-point processors more competitive for this application. In some cases, a DSP plug-in system is used for real-time encoding on a host PC.
AC-3 Applications and Extensions
AC-3, widely known as Dolby Digital, is used in a variety of applications. Dolby Digital provides 5.1 audio channels when used for theatrical motion picture film coding. Data is optically printed between the sprocket holes, with a data rate of approximately 320 kbps. Existing analog soundtracks remain unaffected, providing compatibility.
The Dolby Digital Surround EX system adds a center surround channel. The new channel is matrixed within the left and right surround channels. A simple circuit is used to retrieve the center surround channel.
The Dolby Digital Plus (also known as Enhanced AC-3 or E-AC-3) is an extension format. It primarily adds spectral coding that is used at low bit rates and also supports two additional channels (up to 7.1) and higher bit rates. A core bitstream is coded with Dolby Digital and the two-channel extension is coded as Dolby Digital Plus. Legacy devices that decode only Dolby Digital will not decode Dolby Digital Plus. The Dolby Digital Plus bitstream can be down-converted to yield a Dolby Digital bitstream. However, if the original bitstream contains more than 5.1 channels, the additional channel content appears as a downmix to 5.1 channels.
The Dolby TrueHD is a lossless extension that uses Dolby Digital encoding as its core and Meridian Lossless Packing (MLP) as the lossless codec. Dolby TrueHD can accommodate up to 24-bit word lengths and a 192-kHz sampling frequency. Multi-channel MLP bitstreams include lossless downmixes. For example, a MLP bitstream holding eight channels also contains two- and six-channel lossless downmixes for compatibility with playback systems with fewer channels.
In consumer applications, Dolby Digital is used to code 5.1 audio channels (or fewer) for cable and satellite distribution and in home theater products such as DVD-Video and Blu-ray discs. Dolby Digital is an optional coding format for the DVD-Audio standard. Dolby Digital is also used to code the audio portion of the digital television ATSC DTV standard. It was selected as the audio standard for DTV by the ATSC Committee in 1993, and codified as the ATSC A/52 1995 standard. DVD is discussed in section8 and DTV is discussed in section16. Dolby Digital is not suitable for many professional uses because it was not designed for cascaded operation. In addition, its fixed frame length of 32 ms at 48 kHz does not correspond with video frame boundaries (33.37 ms for NTSC and 40 ms for PAL). Video editing results in data errors and mutes, or loss of synchronization.
Dolby E is a codec used in professional audio applications. It codes up to eight audio channels, provides a 4:1 reduction at 384 kbps to 448 kbps rates, and allows eight to ten generations of encoding and decoding. Using Dolby E, eight audio channels along with metadata describing the contents can be conveyed along a single AES3 interface operating in data mode. A 5.1-channel mix can be easily conveyed and recorded on two-channel media. The data can be recorded, for example, on a VTR capable of recording digital audio; Dolby E's frame rate can be set to match all standard video frame rates to facilitate editing. The metadata carries AC-3 features such as dialogue normalization and dynamic range compression. These coding algorithms were developed by Dolby Laboratories.
DTS Codec
The DTS (Digital Theater Systems) codec (also known as Coherent Acoustics) is used to code multichannel audio in a variety of configurations. DTS can operate over a range of bit rates (32 kbps to 4.096 Mbps), a range of sampling frequencies (from 8 kHz to 192 kHz, based on multiples of 32, 44.1, and 48 kHz) and typically encodes five channels plus an LFE channel. For example, when used to code 48 kHz/16-bit, 5.1-channel soundtracks, bit rates of 768 kbps or 1509 kbps are often used. A sampling frequency of 48 kHz is nominal in DTS coding. Some of the front/surround channel combinations are: 1/0, 2/0, 3/0, 2/1, 2/2, 3/2, 3/3, all with optional LFE. A rear center-channel can be derived using DTS-ES Matrix 6.1 or DTS-ES Discrete 6.1. In addition, the DTS-ES Discrete 7.1 mode is available.
The DTS subband codec uses adaptive differential pulse-code modulation (ADPCM) coding of time-domain data. Input audio data is placed in frames. Five different time durations (256, 512, 1024, 2048, 4096 samples per channel) are available depending on sampling frequency and output bit rate. The frame size determines how many audio samples are placed in a frame. Generally, large frames are used when coding at low bit rates. Operating over one frame at a time, for sampling frequencies up to and including 48 kHz, a multirate filter bank splits the wideband input signal into 32 uniform sub-bands. A frame containing 1024 samples thus places 32 samples in each subband. Either of two polyphase filter banks can be selected. One aims for reconstruction precision while the other promotes coding gain; the latter filter bank has high stopband rejection ratios. In either case, a flag in the bitstream informs the decoder of the choice. Each sub band is ADPCM coded, representing audio as a time domain difference signal; this essentially removes redundancies from the signal. Fourth-order forward adaptive linear prediction is used.
With tonal signals, the difference signal can be more efficiently quantized than the original signal, but with noise like signals the reverse might be true. Thus ADPCM can be selectively switched off in subbands and adaptive PCM coding used instead. In a side chain the audio signal is examined for psychoacoustic and transient information; this can be used to modify the ADPCM coding. For example, the position of a transient in an analysis window is marked and transient modes can be calculated for each sub-band.
A global bit management system allocates bits over all the coded subbands in all the audio channels; its output adapts to signal and coding conditions to optimize coding. The algorithm calculates normalizing scale factors and bit allocation indices and ultimately quantizes the ADPCM samples using from 0 to 24 bits. Because the difference signals are quantized, rather than the actual subband samples, the encoder does not always only use SMR to determine bit allocation. At low bit rates, quantization can be determined by SMR, SMR modified by subband prediction gain, or a combination of both. At high bit rates, quantization determination can combine SMR and differential minimum mean square error. Twenty-eight different mid-tread quantizers can be selected to code the differential signal. The statistical distribution of the differential codes is nonuniform, so for greater coding efficiency, codewords can be represented using variable length entropy coding; multiple code tables are available.
The LFE channel is coded independently of the main channels by decimating a full-bandwidth input PCM bitstream to yield an LFE bandwidth; ADPCM coding is then applied. The decimation can use either 64- or 128 times decimation filters, yielding LFE bandwidths of 150 Hz or 80 Hz. The encoder can also create and embed downmixing data, dynamic range control, time stamp, and user-defined information. Sample-accurate synchronization of audio to video is possible. A joint frequency mode can code the combined high-frequency subbands (excluding the bottom two subbands) from multiple audio channels; this can be applied for low bit-rate applications. Audio frequencies above 24 kHz can be coded as an extension bitstream added to the standard 48 kHz sampling-frequency codec, using side-chain ADPCM encoders. The decoder demultiplexes the data into individual subbands. This data is requantized into PCM data, and then inverse-filtered to reconstruct full bandwidth audio signals as well as the LFE channel. The DTS codec is often used to code the multichannel soundtracks for DVD-Video and Blu-ray titles.
The DTS codec supports XCH and X96 extensions.
XCH (Channel Extension) is also known as DTS-ES. It adds a discrete monaural channel as a rear output. X96 (Sampling Frequency Extension) is also known as Core + 96k or DTS-96/24. It extends the sampling frequency from 48 kHz to 96 kHz by secondarily encoding a residual signal following the baseband encoding. The residual is formed by decoding the encoded baseband and subtracting it from the original signal.
DTS-HD bitstreams contain a core of DTS legacy data (5.1-channel, 48-kHz, typically coded at 768 kbps or 1.509 Mbps) and use the extension option in the DTS bit-stream structure. The DTS-HD codec supports XXCH, XBR, and XLL extensions. XXCH (Channel Extension) adds additional discrete channels. XBR (High Bit-Rate Extension) allows an increase in bit rate. XLL (Lossless Extension) is also known as DTS-HD Master Audio. DTS HD Master Audio is a lossless codec extension to DTS. It uses a sub-stream to accommodate lossless audio compression. Coding can accommodate up to 24-bit word lengths and a 192-kHz sampling frequency. Multichannel bitstreams include lossless downmixes. The DTS-HD High Resolution Audio codec is a lossy extension format to DTS.
Its substream codes data supporting additional channels and higher sampling frequencies. A legacy decoder operates on the core bitstream while an HD-compatible decoder operates on both the core and extension.
The DTS codec used for some commercial motion picture soundtracks is different from that used for consumer applications. Some motion picture soundtracks employ the apt-X100 codec, which uses more conventional ADPCM coding. The apt-X100 system is an example of a subband coder providing 4:1 reduction; however, it does not explicitly reply on psychoacoustic modeling. It operates entirely in the time domain, and uses predictive coding and adaptive bit allocation with adaptive differential pulse code modulation. The audio signal is split into four subbands using QMF banks and analyzed in the time domain. Linear prediction ADPCM is used to quantize each band according to content. Backward adaptive quantization is used in which accuracy of the current sample is compared to the previous sample, and correction is applied with adaption multipliers taken from lookup tables in the encoder. This codes the difference in audio signal levels from one sample to the next; the added noise is white. A 4 bit word is output for every 16-bit input word. The decoder demultiplexes the signal, and applies ADPCM decoding and inverse filtering. A primary asset is low coding delay; for example, at a 32-kHz sampling frequency, the coding delay is a constant 3.8 ms. A range of sampling frequencies and reduction ratios can be used. The apt X100 algorithm was developed by Audio Processing Technology. The DTS algorithms are licensed by Digital Theater Systems, Inc.
A diverse number of lossy codecs have been developed for various applications. Although many are based on standards such as MPEG, some are not. Ogg Vorbis is an example of a royalty-free, unpatented, public domain, open source codec that provides good-quality lossy data compression. It can be used at bit rates ranging from 64 kbps to 400 kbps. Its applications include recording and playback of music files, Internet streaming, and game audio. Ogg Vorbis is free for use in commercial and noncommercial applications, and is available at www.vorbis.com. The latency of Ogg Vorbis encoding makes it unsuitable for speech telephony. Other open source codecs such as Speex may be more suitable.
Speex is available at speex.org.
Meridian Lossless Packing
Meridian Lossless Packing (MLP) is a proprietary audio coding algorithm used to achieve lossless data compression. It is used in applications such as the DVD Audio and Blu-ray disc formats. MLP reduces average and peak audio data rates (bandwidth) and storage capacity requirements. Unlike lossy perceptual coding methods, MLP preserves bit-for-bit content of the audio signal.
However, MLP offers relatively less compression than lossy methods, and the degree of compression varies according to the signal content. In addition, with MLP, the output bit rate continually varies according to audio signal conditions; however, a fixed data rate mode is provided.
Table 2 MLP compression of a two-channel signal is relatively more efficient for higher sampling frequencies.
MLP supports all standard sampling frequencies and quantization may be selected for 16 to 24 bits in single-bit steps. MLP can code both stereo and multichannel signals simultaneously. The degree of compression varies according to the nature of the music data itself. For example, without compression, 96-kHz/24-bit audio consumes 2.304 Mbps per channel, thus a 6-channel recording would consume 13.824 Mbps. This would exceed, for example, the DVD-Audio maximum bit rate of 9.6 Mbps. Even if the high bit rate could be recorded, it would allow only about 45 minutes of music on a single layer DVD-Audio disc with a capacity of 4.7 Gbytes. In contrast, MLP would allow 6-channel 96-kHz/24-bit recordings. It may achieve 38 to 52% of bandwidth reduction, reducing bandwidth to 6.6 Mbps to 8.6 Mbps, allowing a playing time of 73 to 80 minutes on a DVD disc.
In the highest quality DVD-Audio two-channel stereo mode of 192-kHz/24-bit, MLP would provide a playing time of about 117 minutes, versus a playing time of 74 minutes for PCM coding.
Generally, more compression is achieved with higher sampling rates such as 96 kHz and 192 kHz, and less compression is achieved for lower sampling rates such as 44.1 kHz. This is shown in Table 2. Data-rate reduction is measured in bit/sample/channel, both in peak and average rates, where peak rates reflect performance on signals that are difficult to encode. In this table, for example, a peak-data rate reduction of 9 bits/sample means that a 192-kHz 24-bit channel can be coded to fit into a 24 - 9 = 15-bit PCM channel. The peak-rate reduction is important when encoding for any format because of the format's bit rate channel limit. The average-rate reduction indicates the average bit savings and is useful for estimating the storage capacity needed for archiving, mastering, and editing applications. For example, a 192 kHz 24-bit signal might be coded at an average bit rate of 24 - 11.5 = 12.5 bits per channel. This table shows examples of compression for a two-channel recording. Compression increases if the number of channels increases, if channels are correlated, if any of the channels have a low bandwidth, and if any of the channels are lightly used (as with some surround channels).
With MLP, the output peak rate is always reduced relative to the input peak rate.
MLP supports up to 63 audio channels, with sampling frequencies ranging from 32 kHz to 192 kHz and word lengths from 14 to 24 bits. Any word length shorter than 24 bits can be efficiently transmitted and decoded as a 24-bit word by packing zeros in the unused LSBs, without increasing the bit rate. Moreover, this is done automatically without the need for special flagging of word length. In addition, mixed sampling frequencies and word lengths are also automatically supported. The MLP core accepts and delivers PCM audio data; other types of data such as low bit, video, or text cannot be applied to the encoder.

FIG. 25 An example of an MLP encoder showing a lossless matrix, decorrelators,
and Huffman coders. (Stuart, 1998b)
MLP does not discard data during coding; instead, it "packs" the data more efficiently. In that respect, MLP is analogous to computer utilities such as Zip and Stuffit that reduce file sizes without altering the contents (algorithmically, MLP operates quite differently). Data reduction aside, MLP offers other specific enhancements over PCM. Whereas a PCM signal can be subtly altered by generation loss, transmission errors, and other causes as it passes through a production chain, MLP can ensure that the output signal is exactly the same as the input signal by checking the MLP-coded file and confirming its bit accuracy.
The MLP encoder inserts proprietary check data into the bitstream; the decoder uses this check data to verify bit-for bit accuracy. The bitstream is designed to be robust against transmission errors from disc defect or broadcast breakup. Full restart points in the bitstream occur at intervals of between 10 ms to 30 ms, when the content is easy to compress, and hard to compress, respectively.
Errors cannot propagate beyond a restart point. Following a dropout, lossless operation will resume. MLP uses full CRCC checking and minor transmission errors are recovered in less than 2 ms. Recovery from a single bit error occurs within 1.6 ms. Full recovery from burst errors can occur within 10 ms to 30 ms; recovery time may be longer (36 ms to 200 ms) for a simple decoder.
Interpolation may be used to prevent clicks or pops in the audio program. The restart points also allow fast re-cueing of the bitstream on disc. Startup time is about 30 ms and is always less than 200 ms (for complex passages that are difficult to compress). Similarly, fast-speed reviewing of audio material can be accommodated.
MLP applies several processes to the audio signal to reduce its overall data rate, and also to minimize the peak data rate in the variable rate of output data. A block diagram of the encoder is shown in FIG. 25. Data may be remapped to expedite the use of substreams. Data is shifted to account for unused capacity, for example, when less than 24-bit quantization is used or when the signal is not full scale. A lossless matrixing technique is used to optimize the data in each channel, reducing interchannel correlations. The signal in each channel is then decorrelated (inter-sample correlation is reduced) using a separate predictor for each channel. The encoder makes an optimum choice by designing a de-correlator in real time from a large variety of FIR or IIR prediction filters (this process takes into account the generally falling high frequency response of music signals) to code the difference between the estimated and actual signals. A separate predictor is used for each encoded channel.
Either IIR or FIR filters, up to 8th order, can be selected, depending on the type of audio signal being coded. MLP does not make assumptions about data content, nor search for patterns in the data. The decorrelated audio signal is further encoded with entropy coding to more efficiently code the most likely occurring successive values in the bitstream. The encoder can choose from several entropy coding methods including Huffman and Rice coding, and even PCM coding. Multiple data streams are interleaved.
The stream is packetized for fixed or variable data rate.
(Data is encoded in blocks of 160 samples; blocks are assembled into packets and the length of packets can be adjusted, with a default of 10 blocks, or 1600 samples.) A first-in, first-out (FIFO) buffer of perhaps 75 ms is used in the encoder and decoder to smooth the variable data rate.
To allow more rapid startup, the buffer is normally almost empty, and fills when the look-ahead encoder determines that a high entropy segment is imminent. To account for this, the decoder buffer empties. This helps to maintain the data rate below a preset limit, and to reduce the peak data rate.
Because data is matrixed into multiple substreams, each buffered separately, simple decoders can access a subset of the signal. MLP can use lossless matrixing of two sub-streams to encode both a multichannel mix and stereo downmix. Downmix instructions determine some coefficients for the matrices and the matrices perform a transformation so that two channels on one substream decode to provide a stereo mix, and also combine with another substream to provide a multichannel mix. Thus, the addition of the stereo mix adds minimal extra data, for example, one bit per sample.
The MLP bitstream contains a variety of data in addition to the compressed audio data. It also contains instructions to the decoder describing the sampling rate, word length, channel use, and so on. Auxiliary data from the content provider can describe whether speaker channels are from hierarchical or binaural sources, and can also carry copyright, ownership, watermarking data, and accuracy warranty information. There is also CRCC check data, and lossless testing information.
A fixed bit rate can be achieved in a single-pass process if the target rate is not too severe. When the desired rate is near the limit of MLP, a two-pass process is used in which packeting is performed in a second pass with data provided by the encoder. In any case, a fixed bit rate yields less compression than a variable bit rate.
A fixed rate gives predictable file sizes, allows the use of MLP with motion video, and ensures compatibility with existing interfaces. A specific bit rate may be manually requested by the operator. To achieve extra compression, for example, to fit a few more minutes onto a disc data layer, small adjustments may be made to the incoming signal. For example, word length could be reduced by one bit by requantizing (and redithering and perhaps noise shaping) a 24-bit signal to 23 bits. Alternatively, a channel could be lowpass-filtered, perhaps from 48 kHz to 40 kHz.
MLP also allows mixed stream rates in which the option of a variable rate accompanies a fixed-stream rate.
An MLP transcoder can re-packetize a fixed-rate bitstream into a variable-rate stream, and vice versa; this does not require encoding or decoding. Editing can be performed on data while it is packed in the MLP format.
The MLP decoder automatically recognizes MLP data and reverts to PCM when there is no MLP data. Different tracks can intermingle MLP and PCM coding on one disc. Finally, MLP is cascadable; files can be encoded and decoded repeatedly in cascade without affecting the original content.
MLP is optionally used on DVD-Audio and Blu-ray titles.
The MLP bitstream can also be carried on AES3, S/PDIF, IEEE 1384, and other interconnections. MLP was largely developed by Robert Stuart, Michael Gerzon, Malcolm Law, and Peter Craven.
Other lossless codecs have been developed. These codecs include FLAC (Free Lossless Audio Codec), LRC (Lossless Real-time Coding), Monkey's Audio, WavPack, LPAC, Shorten, OptiFROG, and Direct Stream Digital (used in SACD). A lossless WMA codec is part of the Windows Media 9 specification. ALS (Audio Lossless Coding) is used in MPEG-4 ALS. The FLAC lossless codec is free, open-source, and can be used with no licensing fees. FLAC can support PCM samples with a word length from 4 to 32 bits per sample, a wide range of sampling frequencies, and 1 to 8 channels in a bit-stream.
FLAC is available at flac.sourceforge.net. FLAC is free for any commercial or noncommercial applications.